OpenWaiterAI Devlog #1 Instructions
OpenWaiterAI should deal with customers like a real waiter while using the tools flawlessly in the background. For this, we need to figure out what being a real waiter is and what tools are required.
Not all human waiters are the same. Some are just teenagers who need money, some are elite waiters serving elite customers. We want OpenWaiterAI to be like a elite waiters. It should be polite and civilized. Overall serving process should be warm and quick. Customers should like OpenWaiterAI more than average human waiters.

How can we make llms behave like an elite waiter? What is being an elite waiter? For this, we need domain expertise. Best possible solution is to get an elite waiter trainer to join team. He/She should decide how OpenWaiterAI will be. Since i am alone in this project, i will use my own experience from old projects for now. As for the tools, I will discuss them in detail in my next post. But before we continue, we need to understand one of the biggest limitations with today’s LLMs.
Instruction Following
LLMs are foundation models. This means they are designed for general use cases. But with techniques like prompt engineering and fine tuning, we can make them follow certain instructions. Each technique has its own pros and cons.
With prompt engineering, we provide llm a set of instructions. These instructions are written in plain text and given at each call. This technique is best for quick prototyping but is not reliable.
With fine tuning, we show llm how to follow instructions via data. It learns instructions while trying to mimic data. This technique is reliable but requires a reasonable amount of data and expertise.
As you can see below, fine tuning excedes all prompt engineering techniques but is the hardest.
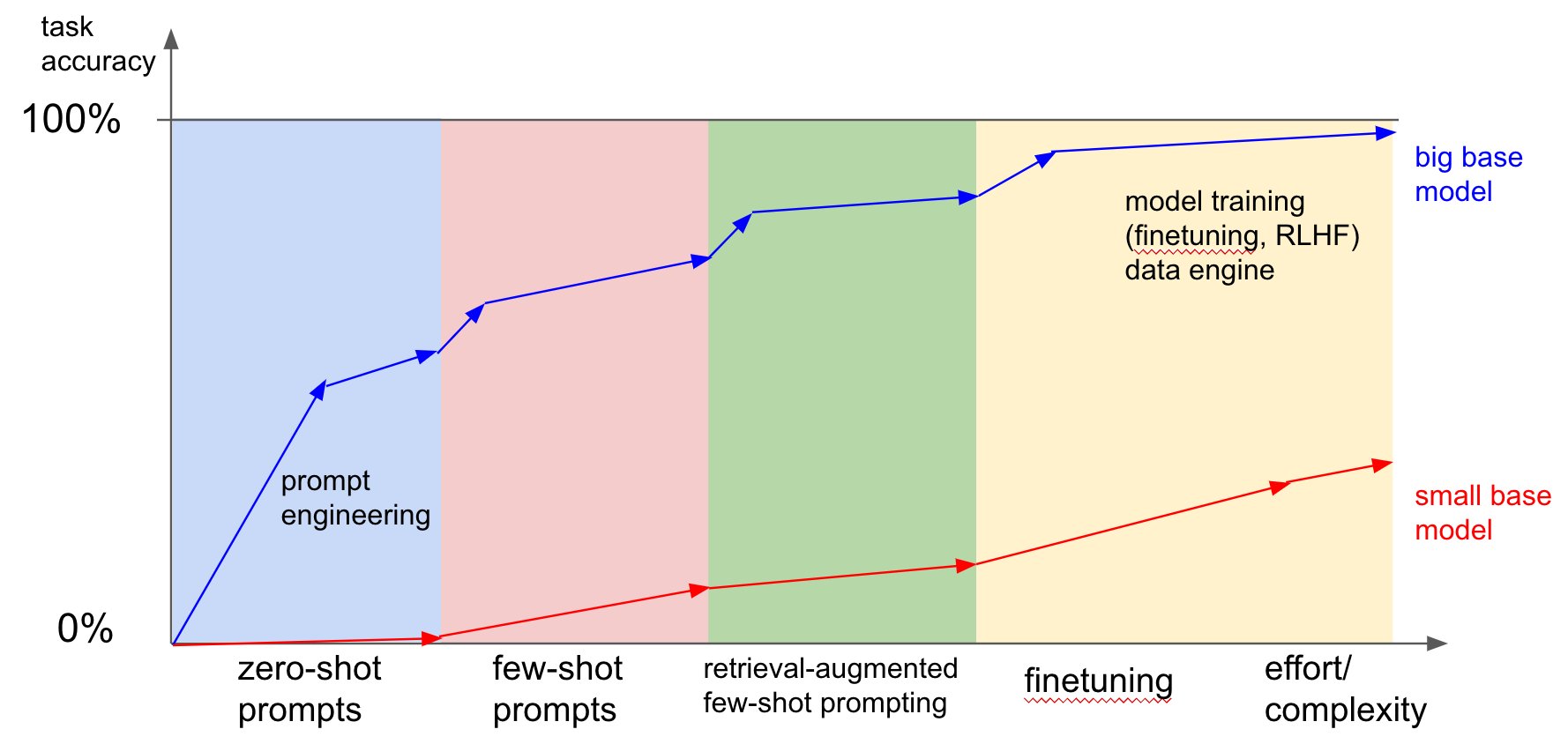 (Credit Andrej Karpathy)
(Credit Andrej Karpathy)
The problem with fine tuning is data. Finding conversational data is hard. Finding domain specific conversational data is even harder. In the case of OpenWaiterAI, how can we acquire the data? Data should contain dialogues between a waiter and customer(s). Will we put microphones to waiters and record their voices? How will we get permissions of customers in this case? And even if customers are okey with this, they will know they are being recorded. Data will not be %100 natural.
I am more fan of collecting data on the way. We will start with prompt engineering. We will create a functional system, collect feedbacks and record non-sensitive data from field. Then fine tune a model. Maybe, we will not need to fine tune a model because this is a well known issue with llms and labs are working on this.
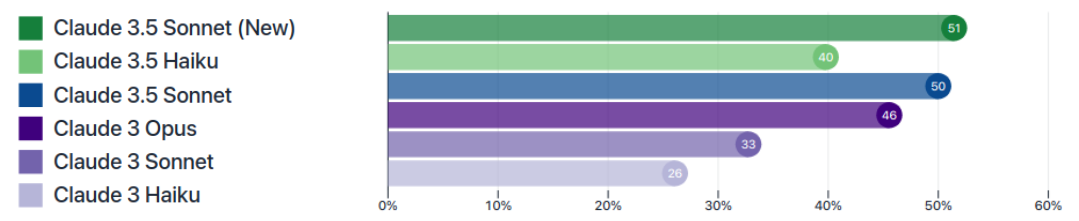 Instruction Following Win Rates
(Source Claude 3.5 Sonnet (New) Model Card)
Instruction Following Win Rates
(Source Claude 3.5 Sonnet (New) Model Card)
Selecting an llm is crucial for prompt engineering. You can not use same prompt with every llm. Different llms from different companies have different styles and capabilities. Therefore deciding on an llm at the beginning will make the development process much easier. As you can see above, even llms from same company can have very different instruction following capabilities. And as you can see below, even if we choose the best llm, its performance may degrade in long scenarios. Knowing limits of your llm is very important because this can change your process workflow, code and infrastructure.
I will use OpenAI’s latest best llm (currently ChatGPT 4o) in this project. But since Langchain is compatible with other llm providers, switching llms should not be a problem.
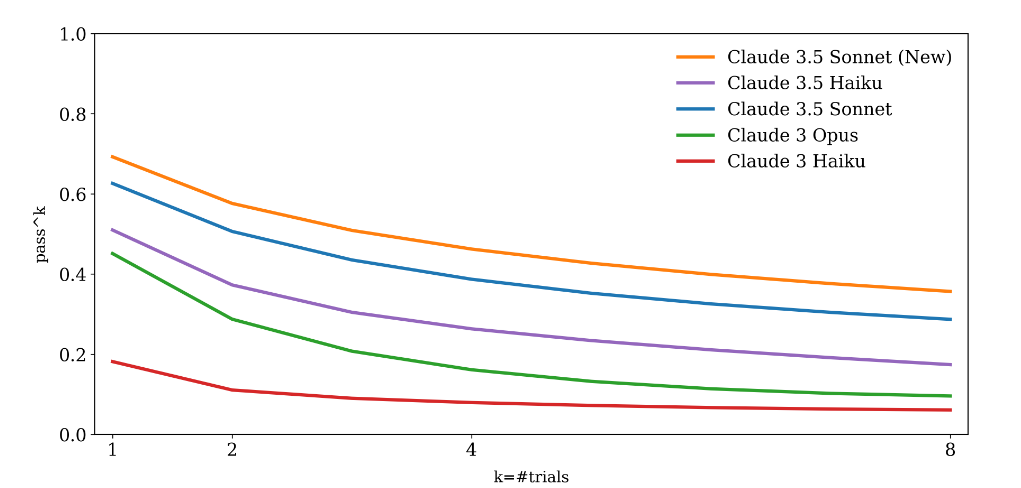 pass^k for TAU-retail
(Source Claude 3.5 Sonnet (New) Model Card)
pass^k for TAU-retail
(Source Claude 3.5 Sonnet (New) Model Card)
Understanding limitations of llm’s instruction following capabilities is very important. Because this means, even if you use the best and the most expensive llm, write the best code and create the best infrastructure, sometimes you will get wrong answers. Even a well fine tuned llm will not give correct answers all the time. Explaining this to non-technical people might be problematic. With all technical papers, benchmarks and expert reports, some morons will not be able to understand this simple limitation!